机器学习(一)模型评估指标

在机器学习建模过程中,针对不同的问题,需采用不同的模型评估指标。
主要分为两大类:分类、回归。
分类
1、混淆矩阵
2、准确率(Accuracy)
3、错误率(Error rate)
4、精确率(Precision)
5、召回率(Recall)
6、F1 score
7、ROC曲线
8、AUC
9、PR曲线
10、对数损失(log_loss)
11、分类指标的文本报告(classification_report)
1、混淆矩阵
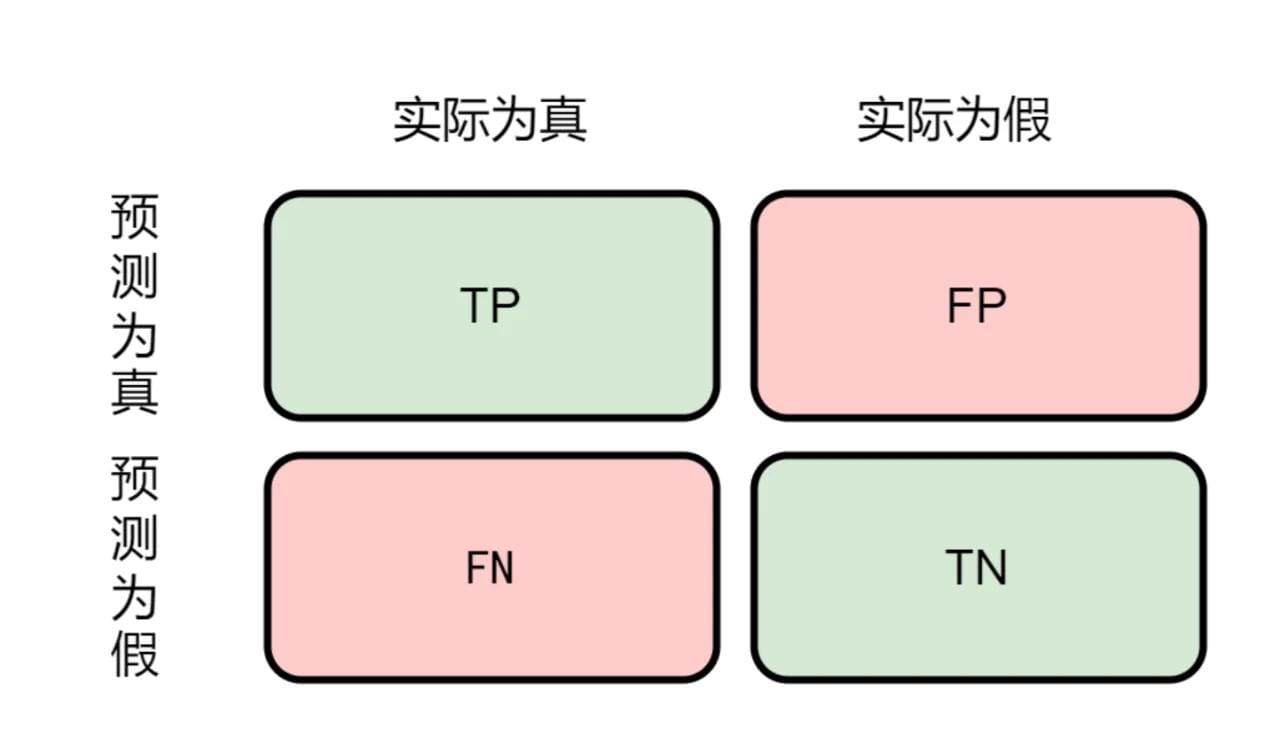
真正(True Positive , TP):被模型预测为正的正样本。
假正(False Positive , FP):被模型预测为正的负样本。
假负(False Negative , FN):被模型预测为负的正样本。
真负(True Negative , TN):被模型预测为负的负样本。
真正率(True Positive Rate,TPR)或灵敏度(sensitivity)
TPR=TP/(TP+FN) ===> 正样本预测结果数 / 正样本实际数
真负率(True Negative Rate, TNR)或特指度/特异度(specificity)
TNR = TN /(TN + FP) ===> 负样本预测结果数 / 负样本实际数
假正率 (False Positive Rate, FPR)
FPR = FP /(FP + TN) ===> 被预测为正的负样本结果数 /负样本实际数
假负率(False Negative Rate , FNR)
FNR = FN /(TP + FN) ===> 被预测为负的正样本结果数 / 正样本实际数
2、准确率(Accuracy)
正确率,是最常用的分类性能指标。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
即正确预测的正反例数 /总数
3、错误率(Error rate)
正确率与错误率是分别从正反两方面进行评价的指标,两者数值相加刚好等于1。正确率高,错误率就低;正确率低,错误率就高。
Error rate = (FP+FN)/(TP+FN+FP+TN)
即错误预测的正反例数/总数
4、精确率(Precision)
只针对预测正确的正样本,表现为预测为正的里面有多少真正是正的。可理解为查准率。
Precision = TP/(TP+FP)
即正确预测的正例数 /预测正例总数
预测为正样本里,有多少判断对的了
5、召回率(Recall)
召回率表现出在实际正样本中,分类器能预测出多少。与真正率相等,可理解为查全率。
Recall = TP/(TP+FN)
即正确预测的正例数 /实际正例总数
原始数据的正样本中,有多少被判断对的了
Precision值和Recall值是既矛盾又统一的两个指标,为了提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall值降低。
6、F1 score
F1 score 又称 F-Measure,是一个综合评价指标。
F值是精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率接近时,F值最大。
很多推荐系统的评测指标就是用F值的。
2/F1 = 1/Precision + 1/Recall
除了F1分数之外,F2分数和F0.5分数在统计学中也得到大量的应用。其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。