Python的多进程、多线程、协程

何为进程、线程、协程
- 进程:运行起来的程序就是进程,是操作系统分配资源的最小单位。
- 线程:线程是进程的组成部分,一个进程可以拥有多个线程,一个线程必须有一个父进程。
- 协程:是线程的更小切分,又称为“微线程”,是一种用户态的轻量级线程。
- 三者关系:进程里有线程,线程里有协程
进程、线程、协程的区别
- 进程:针对于python语言执行环境来说,多进程是利用多核CPU来完成任务,进程拥有独立的内存空间,所以进程间数据不共享,进程之间的通讯是由操作系统完成的,在切换时,CPU需要进行上下文切换,导致通讯效率比较低、开销比较大。
- 线程:多线程是在一个进程内运行,共享进程的内存空间,通讯效率较高、开销较小。但缺点是:因为python底层的GIL锁(global interpeter lock),python的底层的同步锁太多导致多线程被同步很多次,搞成并发效果不佳。
- 协程:一个可以挂起的函数,协程的调度完全由用户控制,用函数切换,开销极小。
多进程、多线程、协程的使用场景
- 多进程:CPU密集运算,大部分时间花在计算
- 多线程、协程:IO密集型(网络IO、磁盘IO、数据库IO),大部分时间花在传输
进程池和map的使用
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
# 进程池
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))
进程Process 类的使用
from multiprocessing import Process
def f(name):
print('hello', name)
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
使用join,主进程跑到join那里,处于挂起状态,看源码,join可以通过设置timeout来决定主进程等待多长时间,若子进程在timeout用完了还没跑完,主进程会杀死子进程。
在进程之间交换对象
multiprocessing 支持进程之间的两种通信通道:
队列
Queue 类是一个近似 queue.Queue 的克隆
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()
队列是线程和进程安全的。
Pipe() 函数返回一个由管道连接的连接对象,默认情况下是双工(双向)
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
进程间同步
multiprocessing 包含来自 threading 的所有同步原语的等价物。例如,可以使用锁来确保一次只有一个进程打印到标准输出:
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()
不使用锁的情况下,来自于多进程的输出很容易产生混淆。
进程间共享状态
如上所述,在进行并发编程时,通常最好尽量避免使用共享状态。使用多个进程时尤其如此。
但是,如果你真的需要使用一些共享数据,那么 multiprocessing 提供了两种方法。
共享内存
可以使用 Value 或 Array 将数据存储在共享内存映射中。例如,以下代码:
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
创建 num 和 arr 时使用的 'd' 和 'i' 参数是 array 模块使用的类型的 typecode : 'd' 表示双精度浮点数, 'i' 表示有符号整数。这些共享对象将是进程和线程安全的。
为了更灵活地使用共享内存,可以使用 multiprocessing.sharedctypes 模块,该模块支持创建从共享内存分配的任意ctypes对象。
服务进程
由 Manager() 返回的管理器对象控制一个服务进程,该进程保存Python对象并允许其他进程使用代理操作它们。Manager() 返回的管理器支持类型: list 、 dict 、 Namespace 、 Lock 、 RLock 、 Semaphore 、 BoundedSemaphore 、 Condition 、 Event 、 Barrier 、 Queue 、 Value 和 Array 。例如
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
进程池
可以创建一个进程池,它将使用 Pool 类执行提交给它的任务。
class multiprocessing.pool.Pool([processes[,initializer[,initargs[,maxtasksperchild[,context]]]]])
一个进程池对象,它控制可以提交作业的工作进程池。它支持带有超时和回调的异步结果,以及一个并行的 map 实现。
- processes 是要使用的工作进程数目。如果 processes 为
None,则使用os.cpu_count()返回的值。 - initializer 不为
None,则每个工作进程将会在启动时调用initializer(*initargs)。 - maxtasksperchild 是一个工作进程在它退出或被一个新的工作进程代替之前能完成的任务数量,为了释放未使用的资源。默认的 maxtasksperchild 是
None,意味着工作进程寿与池齐。 - context 可被用于指定启动的工作进程的上下文。通常一个进程池是使用函数
multiprocessing.Pool()或者一个上下文对象的Pool()方法创建的。在这两种情况下, context 都是适当设置的。
注意,进程池对象的方法只有创建它的进程能够调用。
multiprocessing.pool 对象具有需要正确管理的内部资源 (像任何其他资源一样),具体方式是将进程池用作上下文管理器,或者手动调用 close() 和 terminate()。 未做此类操作将导致进程在终结阶段挂起。
请注意依赖垃圾回收器来销毁进程池是 不正确的 做法,因为 CPython 并不保证进程池终结器会被调用(请参阅 object.__del__() 来了解详情)。
备注
通常来说,Pool 中的 Worker 进程的生命周期和进程池的工作队列一样长。一些其他系统中(如 Apache, mod_wsgi 等)也可以发现另一种模式,他们会让工作进程在完成一些任务后退出,清理、释放资源,然后启动一个新的进程代替旧的工作进程。 Pool 的 maxtasksperchild 参数给用户提供了这种能力。
- apply_async(func[,args[,kwds[,callback[,error_callback]]]]):
apply()方法的一个变种,返回一个AsyncResult对象。如果指定了 callback , 它必须是一个接受单个参数的可调用对象。当执行成功时, callback 会被用于处理执行后的返回结果,否则,调用 error_callback 。如果指定了 error_callback , 它必须是一个接受单个参数的可调用对象。当目标函数执行失败时, 会将抛出的异常对象作为参数传递给 error_callback 执行。回调函数应该立即执行完成,否则会阻塞负责处理结果的线程。 - map(func,iterable[,chunksize]):内置
map()函数的并行版本 (但它只支持一个 iterable 参数,对于多个可迭代对象请参阅starmap())。 它会保持阻塞直到获得结果。这个方法会将可迭代对象分割为许多块,然后提交给进程池。可以将 chunksize 设置为一个正整数从而(近似)指定每个块的大小可以。注意对于很长的迭代对象,可能消耗很多内存。可以考虑使用imap()或imap_unordered()并且显式指定 chunksize 以提升效率。 - map_async(func,iterable[,chunksize[,callback[,error_callback]]]):
map()方法的一个变种,返回一个AsyncResult对象。如果指定了 callback , 它必须是一个接受单个参数的可调用对象。当执行成功时, callback 会被用于处理执行后的返回结果,否则,调用 error_callback 。如果指定了 error_callback , 它必须是一个接受单个参数的可调用对象。当目标函数执行失败时, 会将抛出的异常对象作为参数传递给 error_callback 执行。回调函数应该立即执行完成,否则会阻塞负责处理结果的线程。 - close():阻止后续任务提交到进程池,当所有任务执行完成后,工作进程会退出。
- terminate():不必等待未完成的任务,立即停止工作进程。当进程池对象被垃圾回收时,会立即调用
terminate()。 - join():等待工作进程结束。调用
join()前必须先调用close()或者terminate()。 - get([timeout]):用于获取执行结果。如果 timeout 不是
None并且在 timeout 秒内仍然没有执行完得到结果,则抛出multiprocessing.TimeoutError异常。如果远程调用发生异常,这个异常会通过get()重新抛出。 - wait([timeout]):阻塞,直到返回结果,或者 timeout 秒后超时。
- ready():返回执行状态,是否已经完成。
- successful():判断调用是否已经完成并且未引发异常。 如果还未获得结果则将引发
ValueError。在 3.7 版更改: 如果没有执行完,会抛出ValueError异常而不是AssertionError。
多线程的简单案例
线程可以直接使用全局变量作为共享数据,但是在使用的时候需要添加线程锁
from threading import Thread,Lock
from time import sleep
desk = {
'name' : 0
}
def deposit(studentid,amount):
# 操作共享数据前,申请获取锁
deskLock.acquire()
balance = desk['name']
sleep(0.1)
desk['name'] = balance + amount
print(f'学生 {studentid} 交一本作业,线程 {studentid} 结束')
# 操作完共享数据后,申请释放锁
deskLock.release()
threads = []
deskLock = Lock()
for i in range(1,11):
thread = Thread(target = deposit,args = (i,1))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print('主线程结束')
print(f'最后老师收到的作业为: {desk["name"]}')
线程池的用法
from threading import Lock
from concurrent.futures import ThreadPoolExecutor
from time import sleep
desk = {
'name' : 0
}
def deposit(studentid,amount):
# 操作共享数据前,申请获取锁
deskLock.acquire()
balance = desk['name']
sleep(0.1)
desk['name'] = balance + amount
print(f'学生 {studentid} 交一本作业,线程 {studentid} 结束')
# 操作完共享数据后,申请释放锁
deskLock.release()
deskLock = Lock()
threads = []
with ThreadPoolExecutor(max_workers=5) as t:
for i in range(1,11):
thread = t.submit(deposit, i,1)
print('主线程结束')
print(f'最后老师收到的作业为: {desk["name"]}')
多进程、多线程使用场景案例
怎么样去理解多进程适合计算类型而多线程适合i/o类型呢?请看下面的代码案例,更能直观的展示结果。
多进程案例
def sum_nums(start):
# 计算分段中的数据之和
result = 0
for i in range(start,1000001+start):
result += i
print({"start": start, "result": result})
return result
start_time = time.perf_counter()
with Pool(3) as pool:
s1 = pool.apply_async(sum_nums,(1,))
s2 = pool.apply_async(sum_nums,(1000000,))
s3 = pool.apply_async(sum_nums,(2000000,))
pool.close()
pool.join()
sum = s1.get()+s2.get()+s3.get()
print(sum)
print(f"Time taken: {time.perf_counter() - start_time}")
结果如下图
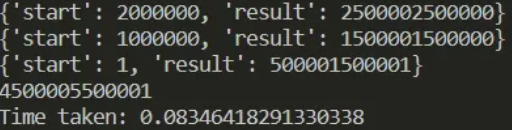
多线程案例
def sum_nums(start):
# 计算分段中的数据之和
result = 0
for i in range(start,1000001+start):
result += i
print({"start": start, "result": result})
return result
start_time = time.perf_counter()
with ThreadPoolExecutor(max_workers=3) as pool:
s1 = pool.submit(sum_nums,(1))
s2 = pool.submit(sum_nums,(1000000))
s3 = pool.submit(sum_nums,(2000000))
sum = s1.result()+s2.result()+s3.result()
print(sum)
print(f"Time taken: {time.perf_counter() - start_time}")
结果如图
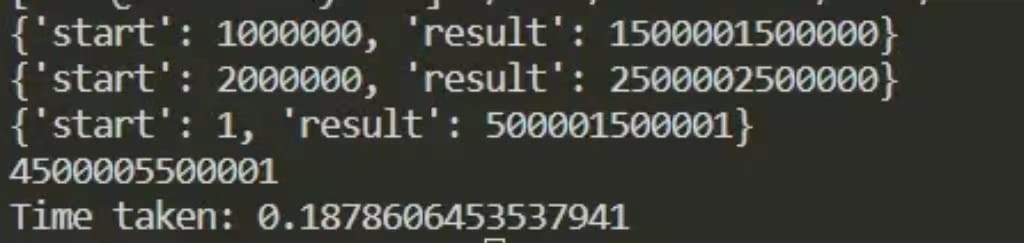
GIL(全局解释锁)
说到协程,我们一般会和线程进行对比,在这个之前我们需要了解下GIL(全局解释锁)。
通常我们使用的解释器都是CPython,GIL导致的结果就是:我们在运行一个Python程序的时候,如果只在一个解释器上运行,即使开了多线程,那也只会用到一个CPU,即同一时间只有一个线程在执行占用CPU运算资源的操作。因此,对于Python来说,只有使用多进程机制处理的任务才属于真正的并行,而多线程属于并发但不属于并行。
协程和线程的区别
线程常用于多任务并行。对于可以切分的IO密集型任务,将切分的每一小块任务分配给一个线程,可以显著提高处理速度。而协程,无论有多少个,都被限定在一个线程内执行,因此,协程又被称为微线程。
从宏观上看,线程任务和协程任务都是并行的。从微观上看,线程任务是分时切片轮流执行的,这种切换是系统自动完成的,无需程序员干预;而协程则是根据任务特点,在任务阻塞时将控制权交给其他协程,这个权力交接的时机和位置,由程序员指定。由此可以看出,参与协程管理的每一个任务,必须存在阻塞的可能,且阻塞条件会被其它任务破坏,从而得以在阻塞解除后继续执行。
尽管协程难以驾驭,但是由于是在一个线程内运行,免除了线程或进程的切换开销,因而协程的运行效率高,在特定场合下仍然被广泛使用。
总结一下:
- 没有线程切换的开销。
- 因为协程都是运行在一个线程上的,不存在由于多线程的”竞争机制“导致的同时写变量冲突等问题。因此,在协程中对于共享资源不需要加锁。
协程简单案例
import asyncio
import time
async def say_after(delay, what):
print("start {}".format(what))
await asyncio.sleep(delay)
print("end {}".format(what))
async def main():
print(f"started at {time.strftime('%X')}")
task1 = asyncio.create_task(say_after(3, 'hello'))
task2 = asyncio.create_task(say_after(2, 'world'))
await task1
await task2
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
join的用法
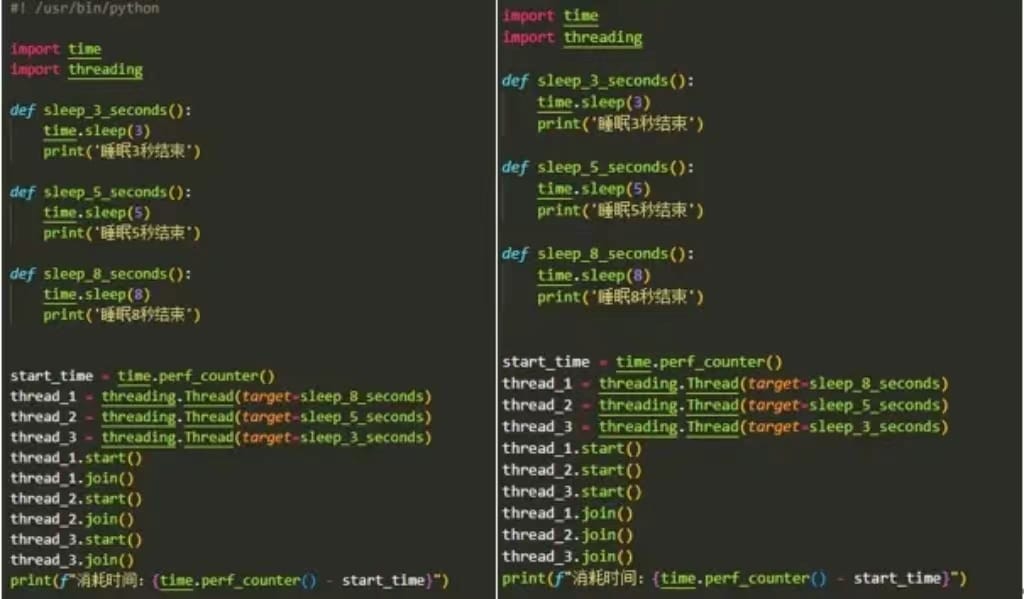
运行结果
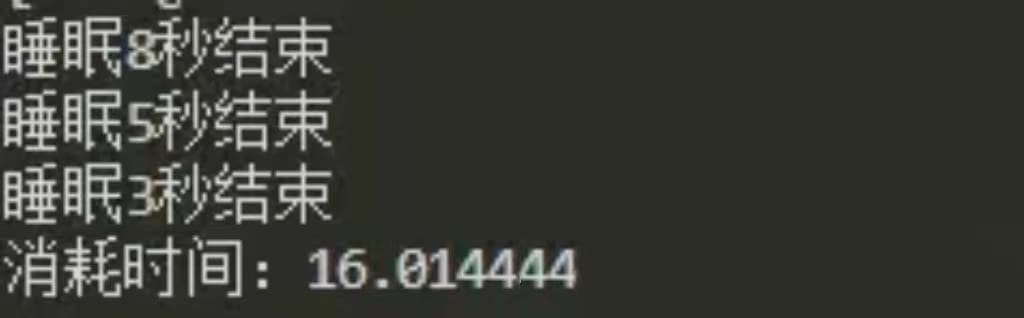
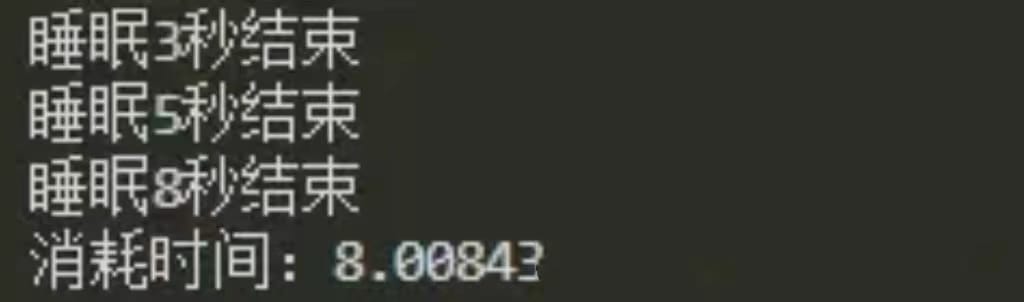
所以,如果代码写为:
thread_1.start()
thread_1.join()
thread_2.start()
thread_2.join()
thread_3.start()
thread_3.join()
当代码运行到thread_1.join()时,主线程就卡住了,后面的thread_2.start()根本没有执行。此时当前只有 thread_1执行过.start()方法,所以此时只有 thread_1再运行。这个线程需要执行8秒钟。等8秒过后,thread_1结束,于是主线程才会运行到thread_2.start(),第二个线程才会开始运行。所以这个例子里面,三个线程串行运行,完全是写代码的人有问题。
而当我们把代码写为:
thread_1.start()
thread_2.start()
thread_3.start()
thread_1.join()
thread_2.join()
thread_3.join()
当代码执行到thread_1.join()时,当前三个子线程均已经执行过.start()方法了,所以此时主线程虽然卡住了,但是三个子线程会继续运行。其中线程3先结束,然后线程2结束。此时线程1还剩3秒钟,所以此时thread_1.join()依然是卡住的状态,直到线程1结束,thread_1.join()解除阻塞,代码运行到thread_2.join()中,但由于thread_2早就结束了,所以这行代码一闪而过,不会卡住。同理,thread_3.join()也是一闪而过。所以整个过程中,thread_2.join()和thread_3.join()根本没有起到任何作用。直接就结束了。
所以,你只需要 join 时间最长的这个线程就可以了。时间短的线程没有 join 的必要。根本不需要把这么多个 join 堆在一起。
为什么会有 join 这个功能呢?我们设想这样一个场景。你的爬虫使用10个线程爬取100个 URL,主线程需要等到所有URL 都已经爬取完成以后,再来分析数据。此时就可以通过 join 先把主线程卡住,等到10个子线程全部运行结束了,再用主线程进行后面的操作。
那么可能有人会问,如果我不知道哪个线程先运行完,那个线程后运行完怎么办?这个时候是不是就要每个线程都执行 join 操作了呢?
确实,这种情况下,每个线程使用 join是合理的:
thread_list = []
for _ in range(10):
thread = threading.Thread(target=xxx, args=(xxx, xxx))
thread.start()
thread_list.append(thread)
for thread in thread_list:
thread.join()